Docente:
Giuseppe Scollo
Università di Catania
Facoltà di Scienze Matematiche, Fisiche e Naturali
Corso di Laurea in Informatica, I livello, AA 2009-10
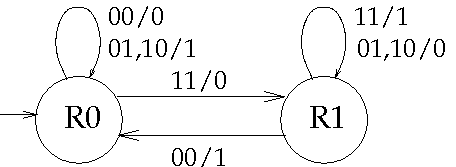
il comportamento di un circuito sommatore può essere facilmente modellato da una FSM con output
possiamo tener conto del riporto da ciascuna posizione alla successiva dotando la macchina di due stati, corrispondenti ai due valori del riporto
la sola differenza di definizione formale tra DFA e NFA sta nel tipo
della funzione di transizione, che per un NFA assegna a uno stato
q e ad un'etichetta
a
l'insieme δ(q, a)
degli stati ai quali l'automa può transire con l'input
a
δ*(q,ε) = {q},
δ*(q,wa) = ∪p∈δ*(q,w)δ(p,a)
coerentemente con tale modifica, e con la condizione di accettazione di
stringhe da un NFA, il linguaggio LA riconosciuto dall'automa non deterministico
A è definito da LA = {w | δ*(q0,w) ∩ F ≠ ∅ }
| x ∈ {0,1}* } :
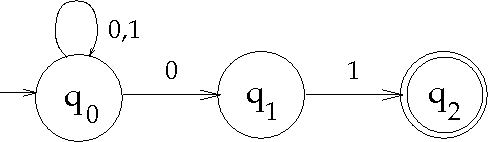
nel caso peggiore, il minimo numero di stati necessari a costruire un DFA equivalente a un NFA dato è esponenzialmente maggiore del numero di stati del NFA, come accade nel seguente caso
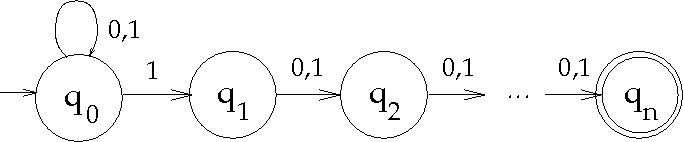
per fortuna, il caso peggiore non sempre si verifica...